ネットワークおよびエンドポイントセキュリティのグローバルリーダー企業である英国ソフォス(日本法人:ソフォス株式会社 東京都港区)は、世界的に実施した調査に関するレポート『The State of Ransomware 2020(ランサムウェアの現状2020年版』を発表しました。この調査結果により、組織がランサムウェア攻撃を受けた際、暗号化されたデータを復元するためにサイバー犯罪者に身代金を支払うことは、被害を回復するための容易で安価な方法ではないことが明らかになりました。実際、組織が身代金を支払うと、被害を回復するのに必要な総費用は約2倍になっています。本調査は、欧州、南北アメリカ、アジア太平洋および中央アジア、中東、およびアフリカを含む6大陸の26カ国の企業の5,000人のIT意思決定者を対象に実施されました。
Adversaries, typically, start moving laterally once they get initial foothold in the victim organization. Once they get initial access, they escalate their privileges and move laterally with the escalated privileges either to propagate their malware or to further reconnaissance & collect the targeted information.
There are many techniques by which threat actors move laterally in the organization. MITRE ATT&CK is one the best resources to start with to understand these various techniques used by the adversaries. MITRE has very well organised these lateral movement techniques under “Lateral Movement” tactic. As a cyber defense team, we should be aware of these techniques and how to detect and prevent them.
In this quick article, I am going to talk about one of the techniques used by the adversaries for moving laterally — SMB Shares. This is one of the most used techniques by adversaries to move laterally in the organization and we should be better prepared to detect it. We will see how Windows Event Logs make this technique highly visible.
How Adversaries Use this technique?
Adversaries abuse the default Windows admin shares that are used by the administrators for legit work. Windows, by default, provides c$, admins$ and IPC$ shares for administrative activities and these shares are accessible through administrative accounts.
Adversaries, once escalated privileges, map these shares from other workstations and copy their malware and move laterally. Moreover, they use windows native services/binaries like net.exe to connect to the shares to reduce any alerts generated by their movement. Following is the command used to map network share — this command maps c$ admin-share of the machine 192.168.189.155.
net use m: \\192.168.189.155\c$ /USER:kirtar
This activity creates a few footprints at the source as well as the target machines.Which logs we need to look for to detect this activity?
How to detect the lateral movement?
This will generate 2 important log entries in Security logs at the source machine.
Event ID 4688 (Sysmon EventID 1): Process Create [ with command line auditing enabled]
EventID 4648: A logon was attempted using explicit credentials.
In a typical organization, normal users do not go around and map the admin shares of the other workstations or the servers. Hence, any Sysmon eventid 1 (4688 — security) for net.exe (mapping admin share/s) from the workstation of the normal users should be investigated.
EventID 1 (4688 with command line parameters) provides following key details
-Current Process with its full path
-Description
-Original File Name
-Command Line parameters passed with the binary while executed
-Current directory of the user
-the account/user who has spawn this process
-hashes for the process binary image
-Parent Process
-Parent Process command line parameters
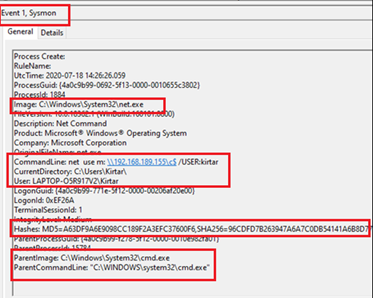
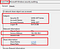
The following screenshot shows that c$ share is mapped of the machine with IP Address 192.168.189.155 by using account of LAPTOP-O5R917V2\kirtar. The parent process shows that net.exe is executed via cmd.exe. The details related to hash, parent process command lines, image path can be seen in the screenshot.
This gives us crucial information about potentially compromised account and machine along with the machine(destination) where adversaries might have copied their malware.
Figure 1. Sysmon EventID 1 at Source — Process Create (net.exe)
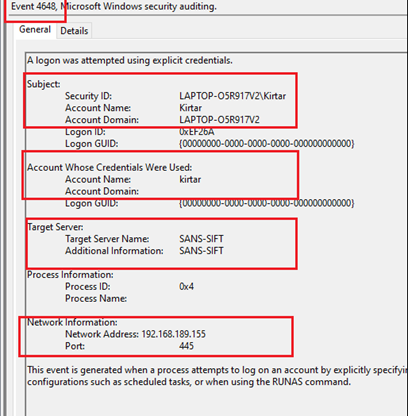
The other log generated at the source is 4648. This log is generated as attacker uses an explicit credential to map the network share. This event provides very important information about the destination IP & hostname and both of the accounts (original and switched). This information will help us to substantiate the information received from the previous event. Look at the snapshot below.
Figure 2. 4648 (explicit credentials used)
As shown in the screenshot, the original account is LAPTOP-O5R917V2\kirtar and the switched account kirtar (this is used for authenticating to the remote machine). The hostname of the target machine SANS-SIFT. Furthermore, Network Information provides the destination IP address (192.168.189.155) — this can be verified against the command-line parameters of the previous event.
Detection at the Destination
The same command generates a few logs on the destination machine as well. Following logs are generated at the destination.
4776 — The computer attempted to validate the credentials for an account
4672 — Special privileges assigned to new logon
4624 (Type 3) — An account was successfully logged on
Figure 3. Typical trilogy for local authentication with administrative privileges
Look at the time for all these 3 events, they are logged at nearly same time. These events are generated because local NTLM authentication (4776) happens over the network (Type3) via local administrative account (4672).
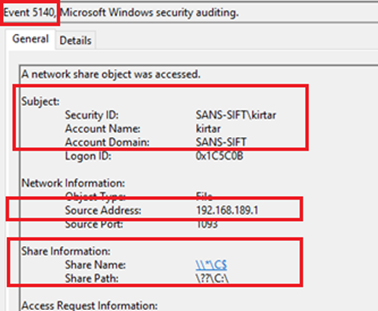
One of the key logs generated at the destination is EventID 5140. This is “the log” for the actual event — network share access.
This log provides the following information
-the account used for accessing/mapping the share
-IP address of the source machine (from where the share is accessed)
-Name and Path of the share
Please see the following screenshot of 5140 EventID generated as a result of the command that we ran above. It shows that account Sans-SIFT\kirtar is used to access the C$ share. The IP of the source machine from where this share is accessed is 192.168.189.1.
Figure 4. EventID 5140 (A network share object was accessed.)
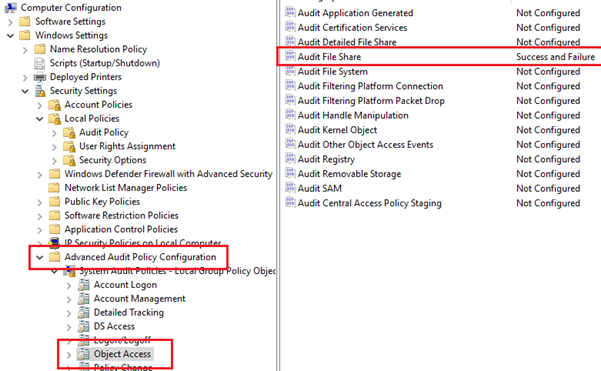
There are couple of caveats related to this log (5140). This log is not enabled by default, this needs to be enabled via GPO by enabling “File Share” auditing under “Object Access” in Advanced Audit Policy Configuration settings. Secondly, it is available in 2008R2+ editions. Look at the following screenshot that shows the audit policy configuration required for 5140.
Figure 5. Audit Policy configuration for 5140
So, as we have seen there are quite a few windows security event logs that can be leveraged to detect this lateral movement. Creating Alerts based on the precise filters will help in improving precision and reducing false positives in detecting lateral movement.
Similarly, event logs can be used to detect other lateral movement techniques as well. I will try to write articles for other techniques as well.
That’s it for now. Thanks for reading and happy hunting fellas !!
もちろん、扱う情報や業界規制等によって取るべきセキュリティ対策のレベルを見直すことも重要です(個人情報を保有する or しない、クレジットカード情報や金融系取引情報を扱う or 扱わない、などで守り方の温度感も変わってきます)。
すべてのサービス層で重厚なセキュリティ対策を施すと対応に必要な工数が増えたり、運用の手間が増えてしまうため、スコープの見極めは大切です。
Clair uses alpine-secdb. However, the purpose of this database is to make it possible to know what packages has backported fixes. As README says, it is not a complete database of all security issues in Alpine. Trivy collects vulnerability information in Alpine Linux from Alpine Linux aports repository. Then, those vulnerabilities will be saved on vuln-list.
alpine-secdb has 6959 vulnerabilities (as of 2019/05/12). vuln-list has 11101 vulnerabilities related to Alpine Linux (as of 2019/05/12). There is a difference in detection accuracy because the number of vulnerabilities is nearly doubled.
以上の理由より、導入と利用が簡単かつ高精度なtrivyを採用することにしました。
Dockle
Dockleは天地知也さんが開発したコンテナイメージに含まれるセキュリティホールをチェックしてくれるツールです。
hadolintとは異なり、Dockerfileではなくイメージに対するスキャンであり、ベースOSイメージ側の設定内容に関しても踏み込んでスキャンしてくれる点が特徴です。
また、CIS(Center for Internet Security)と呼ばれる国際的なインターネットセキュリティ標準化に取り組む団体が提供しているベンチマークに対する遵守状況もチェックしてくれます。